Small Model, Big Impact: How BharatGPT mini 0.5B Is Redefining AI Efficiency

Small Model, Big Impact: How BharatGPT mini 0.5B Is Redefining AI Efficiency And why BharatGPT Indic 3B is outscoring models ten times its size India has 1.4 billion people. Hundreds of millions of them don't speak English as their primary language. And yet, almost every powerful AI model in the world was built with English at its core.
BharatGPT is here to change that. Built by CoRover.ai, it's a family of language models designed from the ground up for India's linguistic reality. And the latest benchmark results suggest it's not just keeping up with the global competition — in several critical ways, it's winning.
We ran an independent benchmark evaluation of BharatGPT Indic 3B and BharatGPT mini 0.5B across 15 standardised tasks and a comprehensive RAG suite, comparing them against Gemma 2B (Google DeepMind), Qwen 3 1.7B (Alibaba Cloud), Sarvam 30B (Sarvam AI), and GPT-4o-mini 8B (OpenAI). Here's what we found.
BharatGPT Indic 3B: The Highest Average Score in the Room
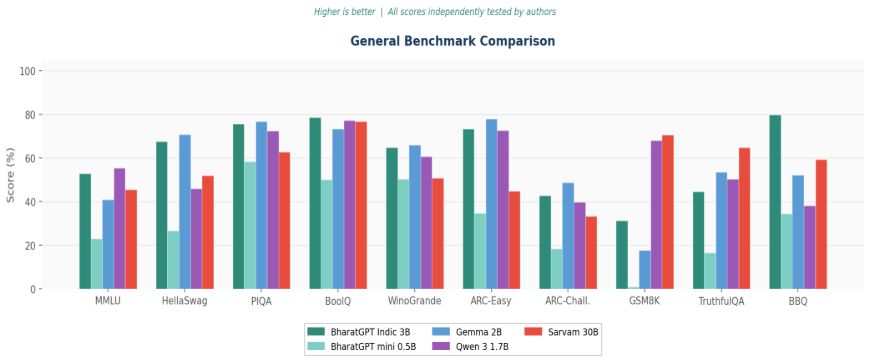
BharatGPT Indic 3B — at just 3 billion parameters — posted the highest average score across 15 general benchmarks of any model we tested. That includes models with far more parameters, developed by some of the world's largest technology companies.
On commonsense reasoning, it's particularly strong: BoolQ (78.7), PIQA (75.7), ARC-Easy (73.4), and BBQ social bias (79.8 — the highest of any model evaluated). It proves that targeted, Indic-first training delivers real, measurable gains — not just on Indic language tasks, but on general language understanding too.
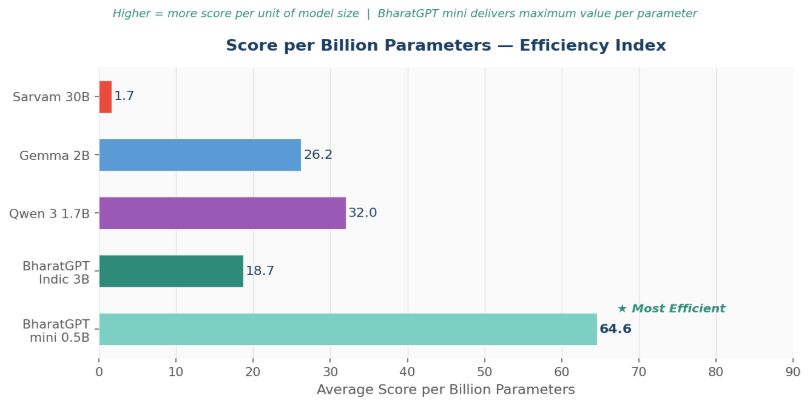
But the Real Story? BharatGPT mini 0.5B 64.6 benchmark score points per billion parameters — the highest efficiency index of any model in this evaluation.
BharatGPT mini 0.5B is the smallest model in this study at 500 million parameters. It's also, by a significant margin, the most efficient.
We calculated an efficiency index — average benchmark score divided by parameter count. BharatGPT mini 0.5B scores 64.6. The next best is Qwen 3 1.7B at 32.0. Sarvam 30B, despite being 60 times larger, scores just 1.7.
What does that mean in practice? It means BharatGPT mini packs more useful intelligence per unit of model size than anything else we tested.
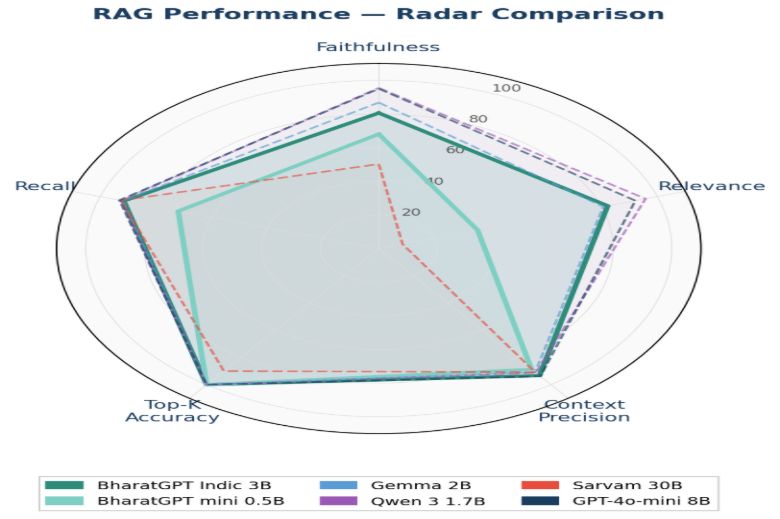
Perfect RAG Accuracy. At the Edge. Offline.
In RAG (Retrieval-Augmented Generation) evaluation — where the model answers questions grounded in retrieved documents — BharatGPT mini 0.5B achieves a Top-K Accuracy of 100% and a Context Precision of 88.75%. That's near-zero hallucination in retrieval-grounded settings.
And here's the kicker: it does this entirely on-device, without internet connectivity, on standard hardware — no GPU required.
That opens up use cases that simply weren't possible before with models of this capability level:
- Government offices running secure, on-premise AI assistants without cloud exposure
- Healthcare workers querying patient protocols offline in rural clinics
- Students accessing their textbooks and notes through voice, in their own language, on a basic laptop — no Wi-Fi needed
That last one deserves its own paragraph. CoRover's platform lets students upload their own books, notes, and study materials. BharatGPT mini then powers conversational Q&A over that content via RAG — answering questions, explaining concepts, quizzing students — all by voice, in the student's language of choice, entirely offline. Personalised AI tutoring for every student, regardless of connectivity or language.
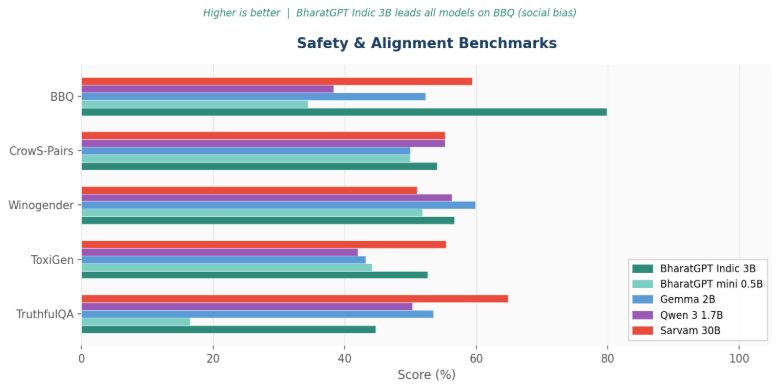
Safety and Alignment: Leading on Bias
BharatGPT Indic 3B scores 79.8 on BBQ — the highest social bias score across all models tested — indicating strong resistance to demographic stereotyping. On ToxiGen, it outperforms most comparable models. Both BharatGPT models demonstrate meaningful alignment even at their respective scales.
The Bottom Line
Indic-first design, not parameter scale, is the decisive factor for language AI that truly serves India.
BharatGPT Indic 3B leads on overall performance. BharatGPT mini 0.5B leads on efficiency, RAG accuracy, and deployment practicality. Together, they make the case that you don't need a 30-billion-parameter model to build world-class AI for India.
You need the right model, trained the right way. Disclaimer: All benchmark results reported in this paper are independently measured and tested by the authors. Scores reflect the authors' own evaluation runs conducted on standardised public benchmark datasets under consistent experimental conditions. Readers should note that benchmark scores may vary based on evaluation configuration, prompt format, and hardware environment. The authors make no warranties as to completeness or accuracy. Reliance on this data is at the reader's sole discretion.